Pipelines Quickstart
Beta
This Kubeflow component has beta status. See the Kubeflow versioning policies. The Kubeflow team is interested in your feedback about the usability of the feature.Use this guide if you want to get a simple pipeline running quickly in Kubeflow Pipelines.
- This quickstart guide shows you how to use one of the samples that come with the Kubeflow Pipelines installation and are visible on the Kubeflow Pipelines user interface (UI). You can use this guide as an introduction to the Kubeflow Pipelines UI.
- The end-to-end tutorial shows you how to prepare and compile a pipeline, upload it to Kubeflow Pipelines, then run it.
Deploy Kubeflow and open the pipelines UI
Follow these steps to deploy Kubeflow and open the pipelines dashboard:
-
Follow the guide to deploying Kubeflow on GCP.
Due to kubeflow/pipelines#1700, the container builder in Kubeflow Pipelines currently prepares credentials for Google Cloud Platform (GCP) only. As a result, the container builder supports only Google Container Registry. However, you can store the container images on other registries, provided you set up the credentials correctly to fetchthe image.
-
When Kubeflow is running, access the Kubeflow UI at a URL of the form
https://<deployment-name>.endpoints.<project>.cloud.goog/, as described in the setup guide. The Kubeflow UI looks like this: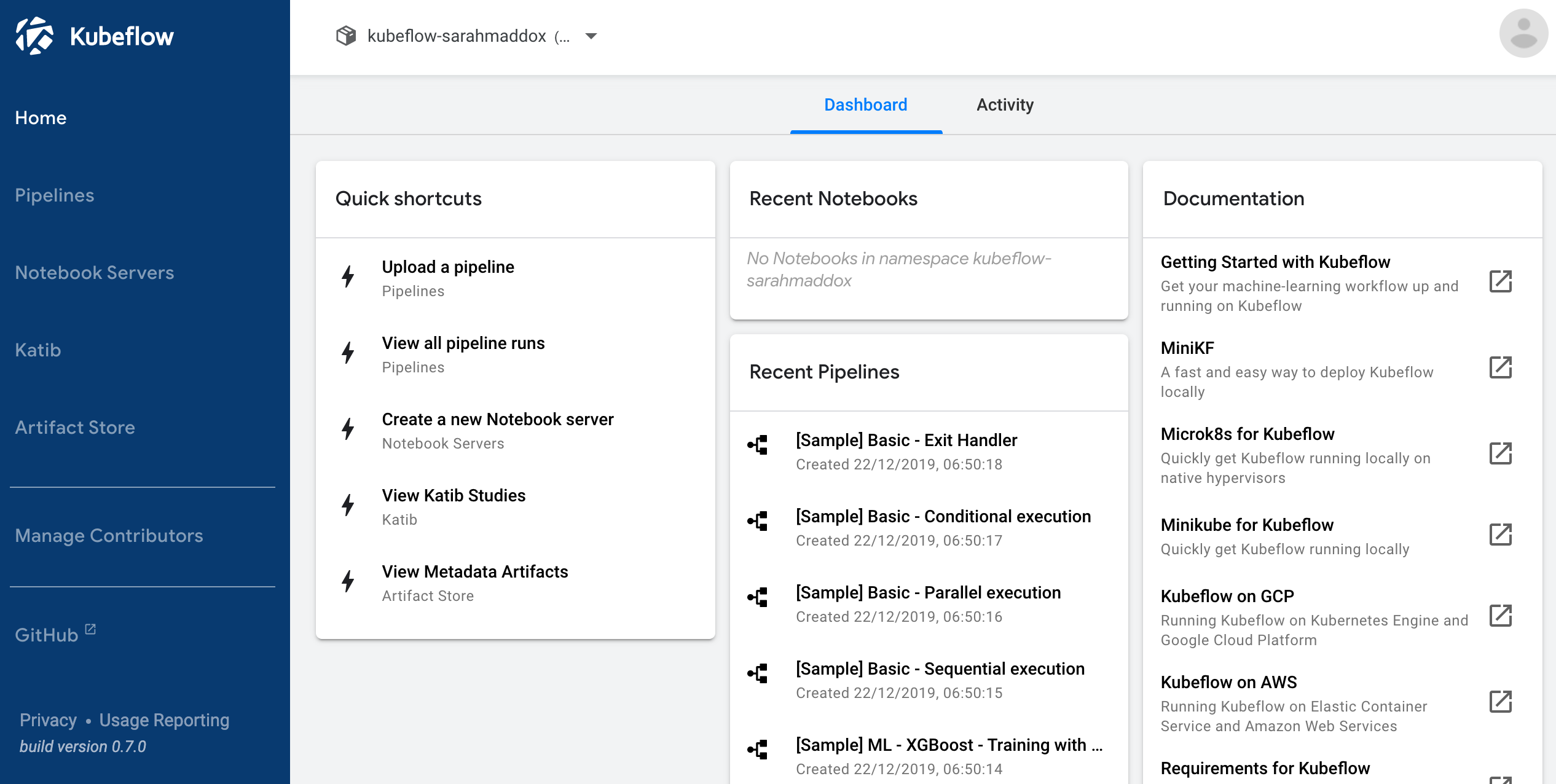
If you skipped the Cloud IAP option when deploying Kubeflow, or if you haven’t yet set up your Kubeflow endpoint, you can access Kubeflow via
kubectland port-forwarding:-
Install
kubectlif you haven’t already done so, by running the following command on the command line:gcloud components install kubectl. For more information, see thekubectldocumentation. -
Run
kubectl port-forward -n kubeflow svc/ml-pipeline-ui 8080:80and go tohttp://localhost:8080/.
-
-
Click Pipelines to access the pipelines UI. The pipelines UI looks like this:
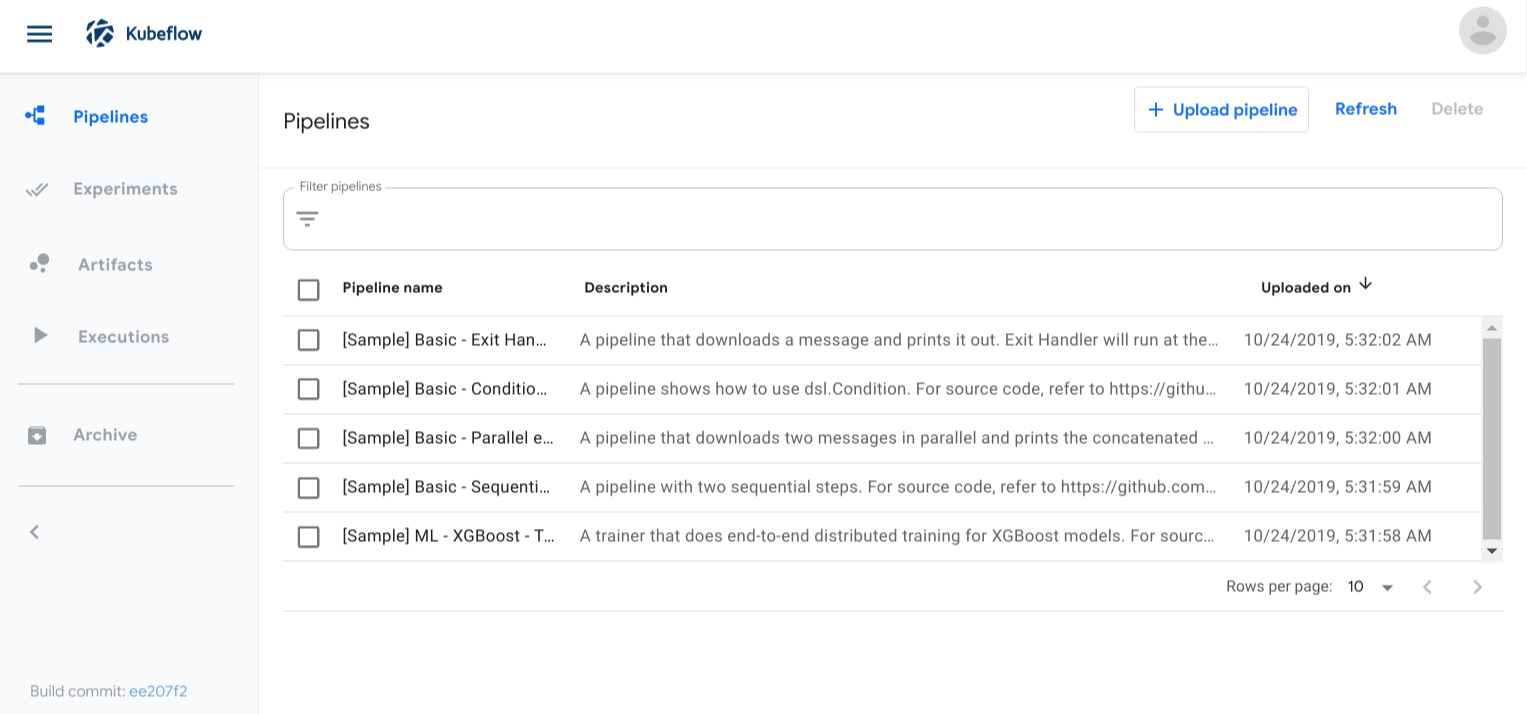
Run a basic pipeline
The pipelines UI offers a few samples that you can use to try out pipelines quickly. The steps below show you how to run a basic sample that includes some Python operations, but doesn’t include a machine learning (ML) workload:
-
Click the name of the sample, [Sample] Basic - Parallel Execution, on the pipelines UI:
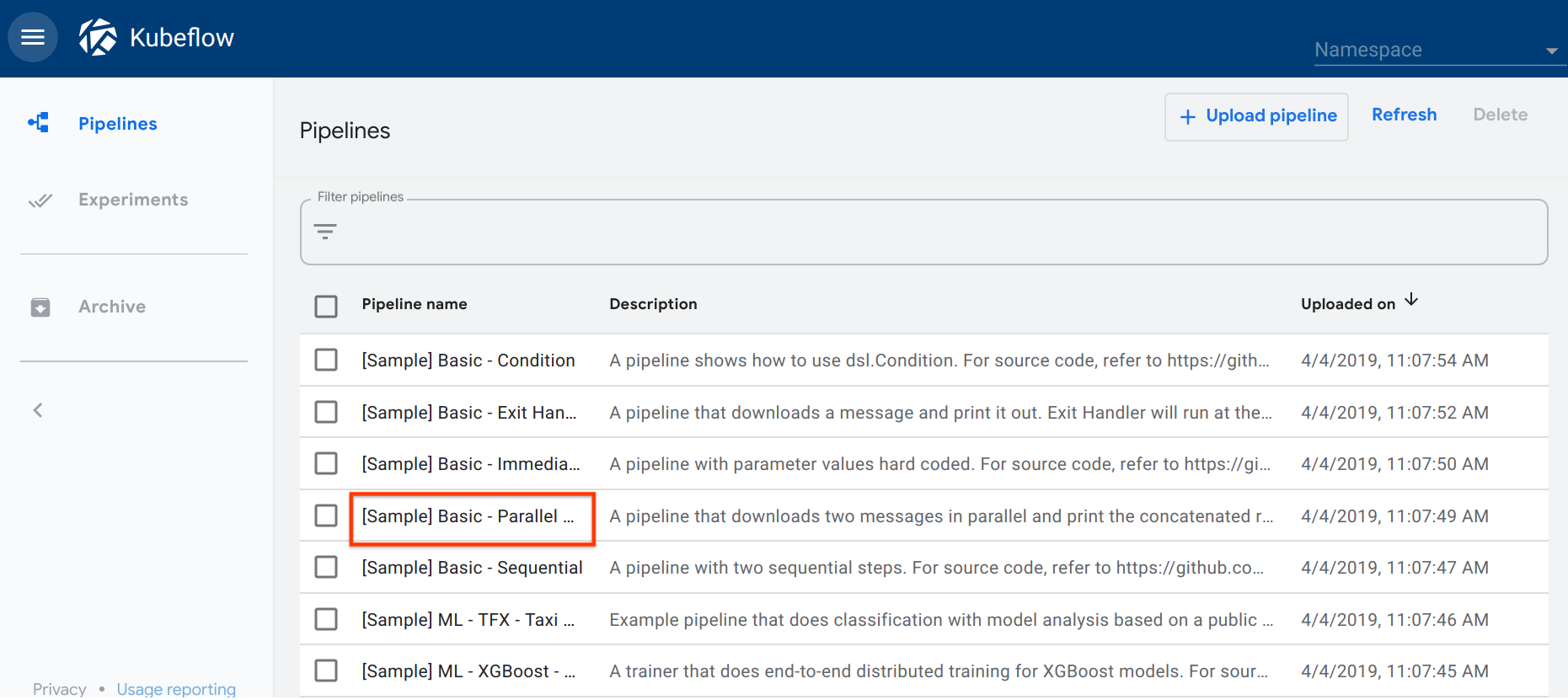
-
Click Create experiment:
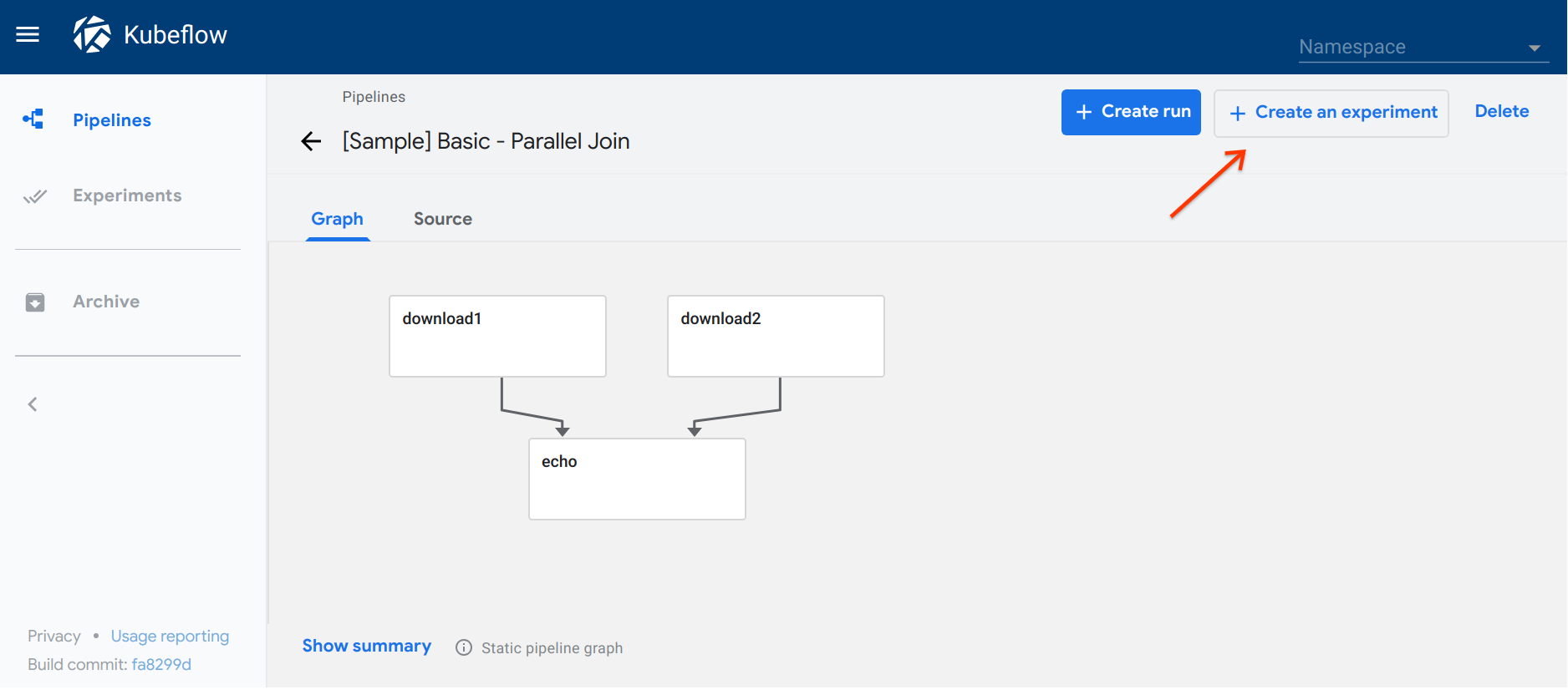
-
Follow the prompts to create an experiment and then create a run. The sample supplies default values for all the parameters you need. The following screenshot assumes you’ve already created an experiment named My experiment and are now creating a run named My first run:
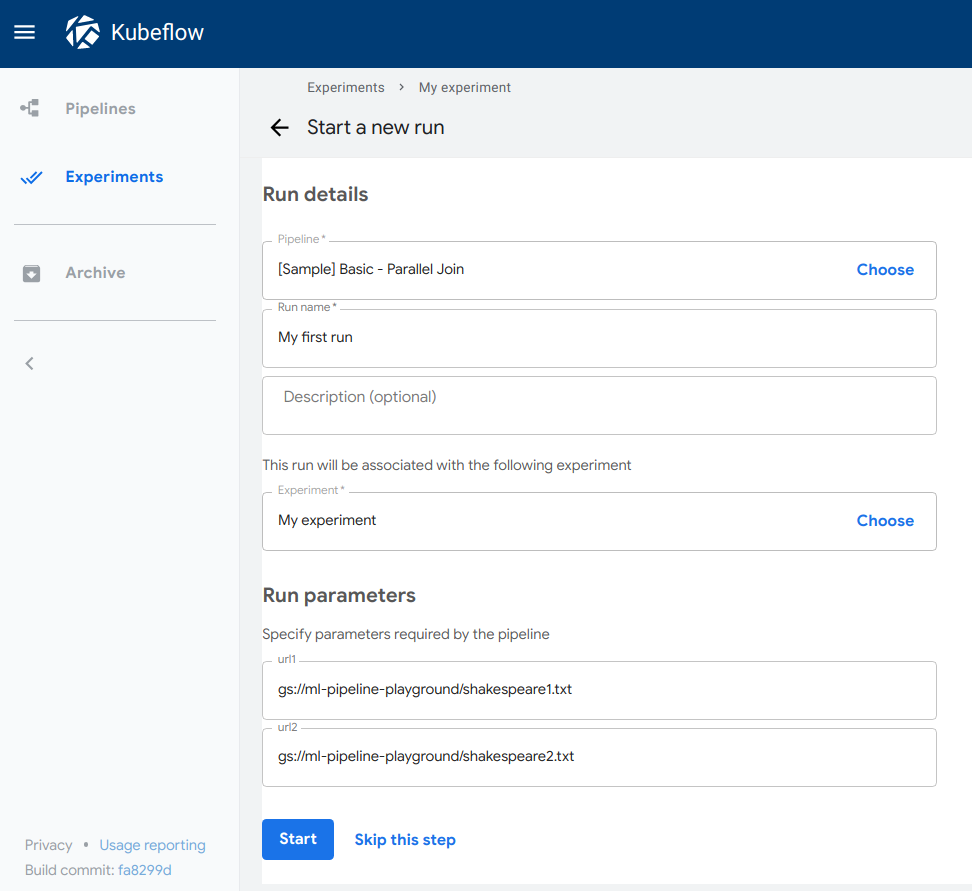
-
Click Start to create the run.
-
Click the name of the run on the experiments dashboard:
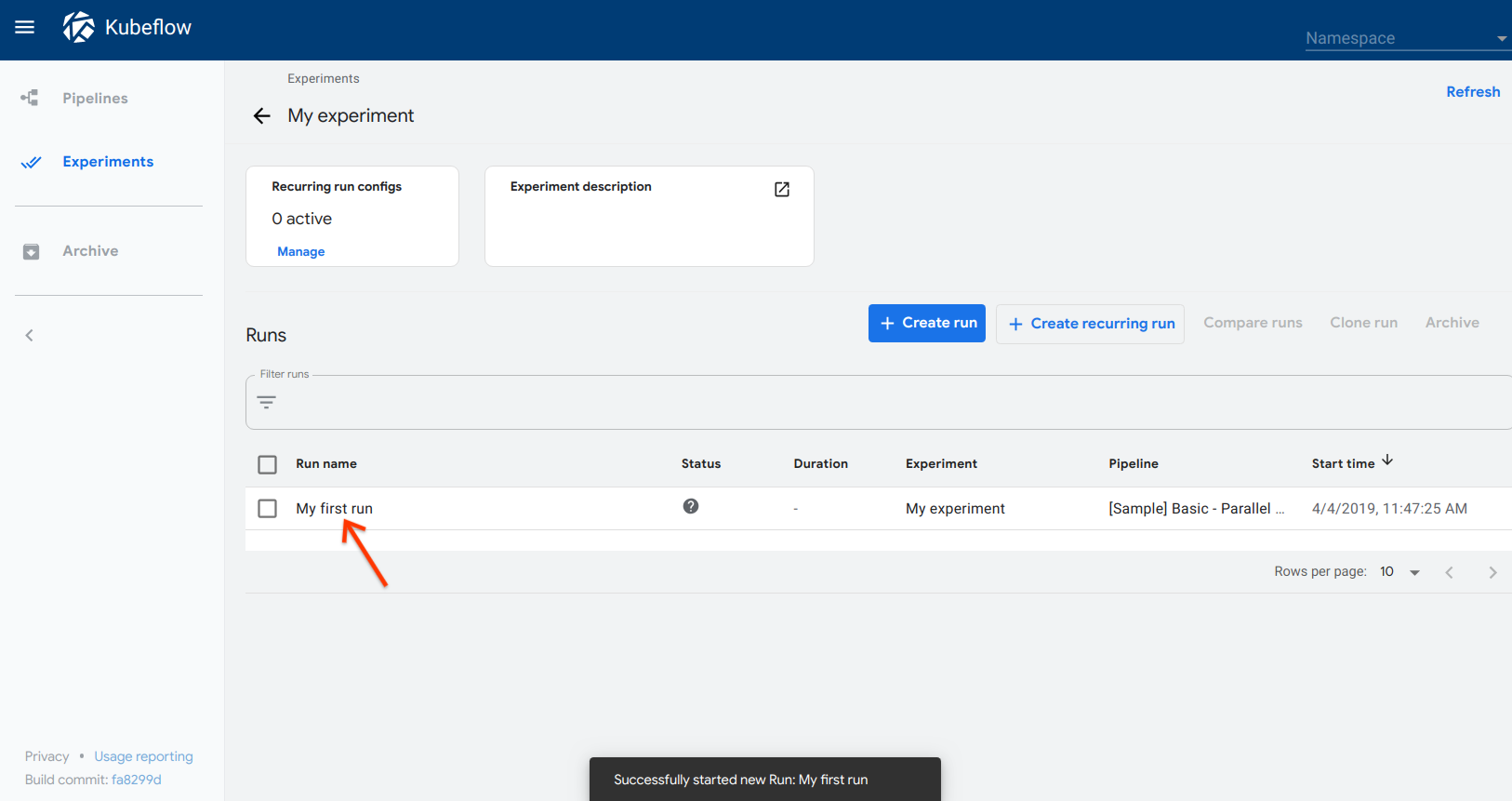
-
Explore the graph and other aspects of your run by clicking on the components of the graph and the other UI elements:
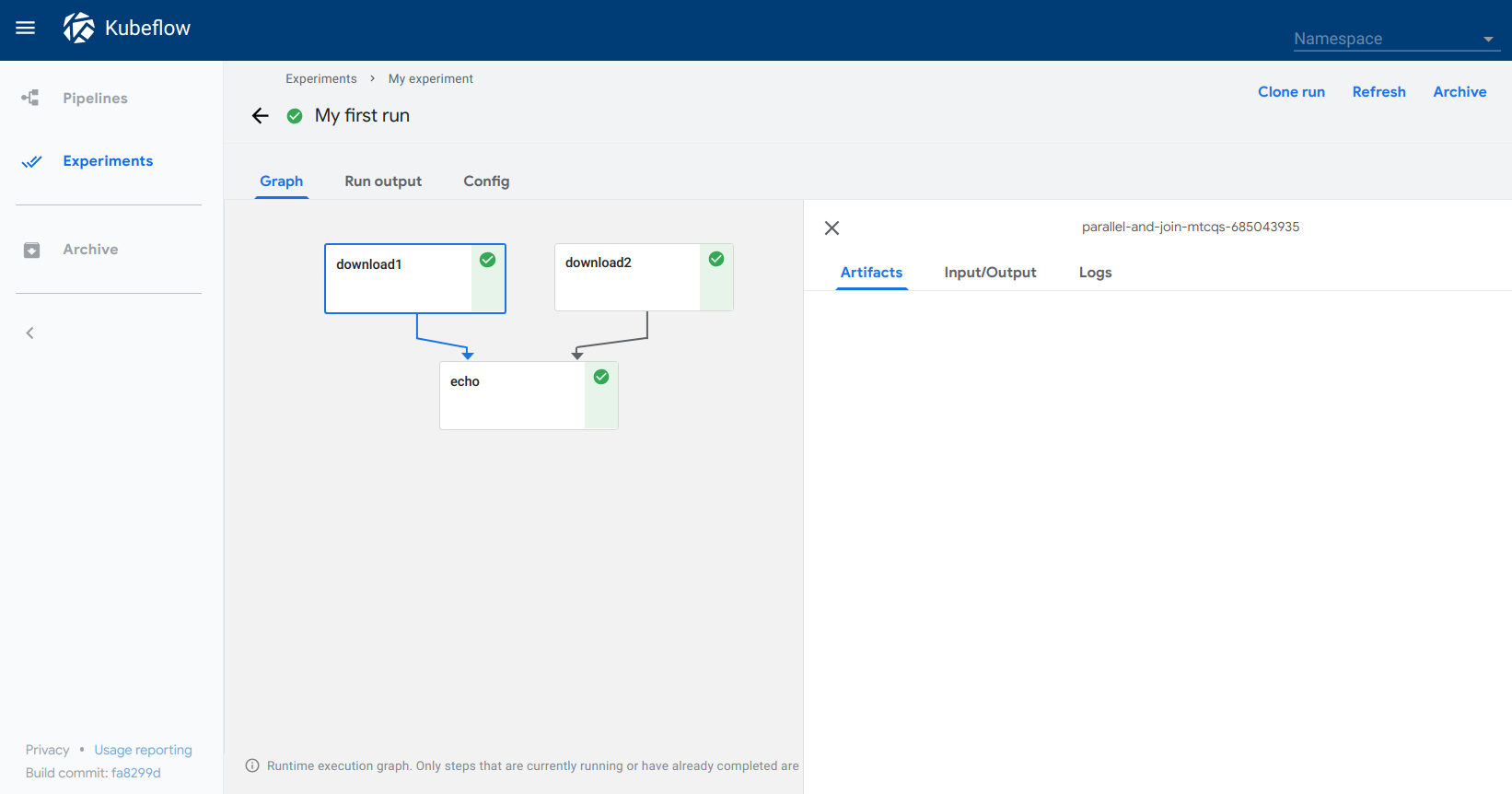
You can find the source code for the basic parallel join sample in the Kubeflow Pipelines repo.
Run an ML pipeline
This section shows you how to run the XGBoost sample available from the pipelines UI. Unlike the basic sample described above, the XGBoost sample does include ML components. Before running this sample, you need to set up some GCP services for use by the sample.
Follow these steps to set up the necessary GCP services and run the sample:
-
In addition to the standard GCP APIs that you need for Kubeflow (see the GCP setup guide), ensure that the following APIs are enabled:
-
Create a Cloud Storage bucket to hold the results of the pipeline run.
- Your bucket name must be unique across all of Cloud Storage.
- Each time you create a new run for this pipeline, Kubeflow creates a unique directory within the output bucket, so the output of each run does not override the output of the previous run.
-
Click the name of the sample, [Sample] ML - XGBoost - Training with Confusion Matrix, on the pipelines UI:
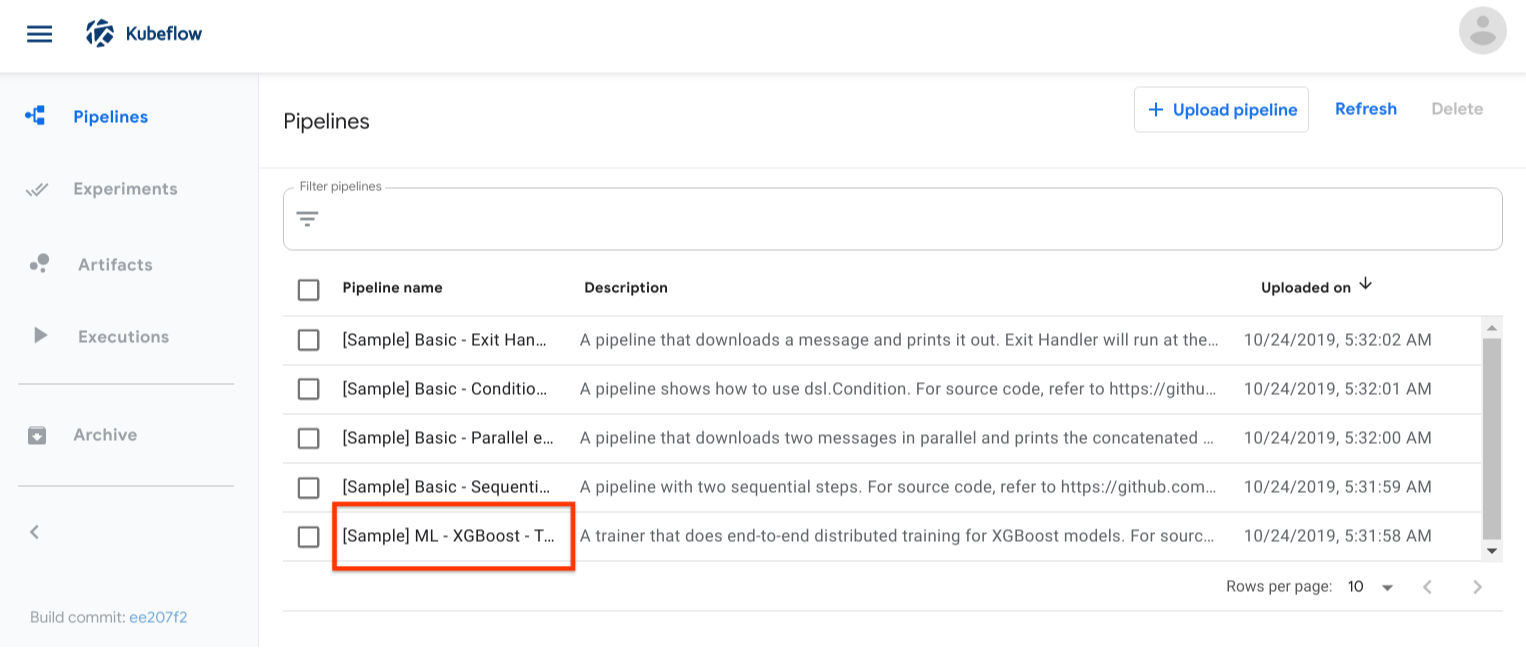
-
Click Create experiment.
-
Follow the prompts to create an experiment and then create a run. Supply the following run parameters:
- output: The Cloud Storage bucket that you created earlier to hold the results of the pipeline run.
- project: Your GCP project ID.
The sample supplies the values for the other parameters:
- region: The GCP geographical region in which the training and evaluation data is stored.
- train-data: Cloud Storage path to the training data.
- eval-data: Cloud Storage path to the evaluation data.
- schema: Cloud Storage path to a JSON file describing the format of the CSV files that contain the training and evaluation data.
- target: Column name of the target variable.
- rounds: The number of rounds for XGBoost training.
- workers: Number of workers used for distributed training.
- true-label: Column to be used for text representation of the label output by the model.
The following partial screenshot shows the run parameters, including the two parameters that you must supply:
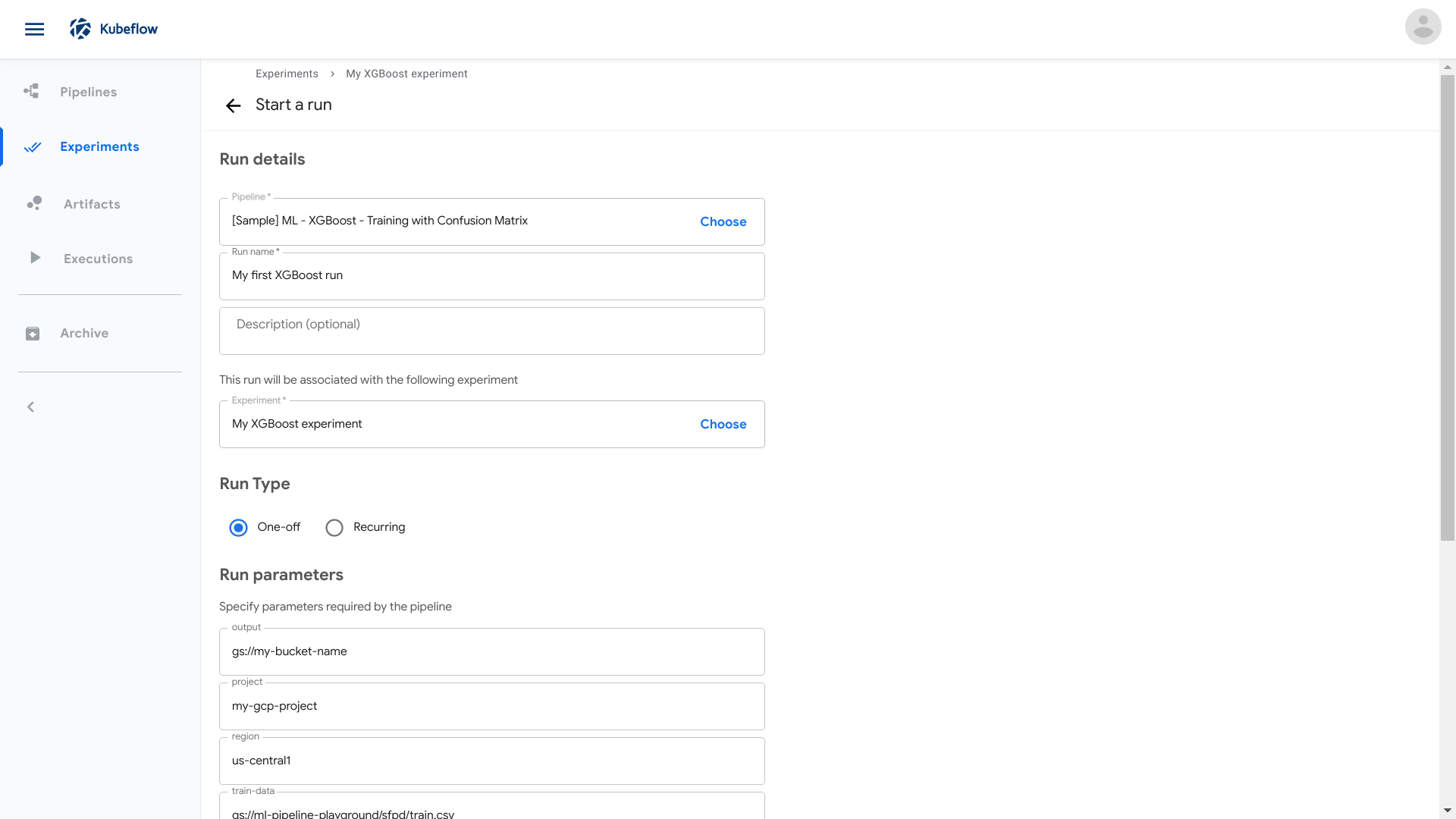
-
Click Start to create the run.
-
Click the name of the run on the experiments dashboard.
-
Explore the graph and other aspects of your run by clicking on the components of the graph and the other UI elements. The following screenshot shows the graph when the pipeline has finished running:
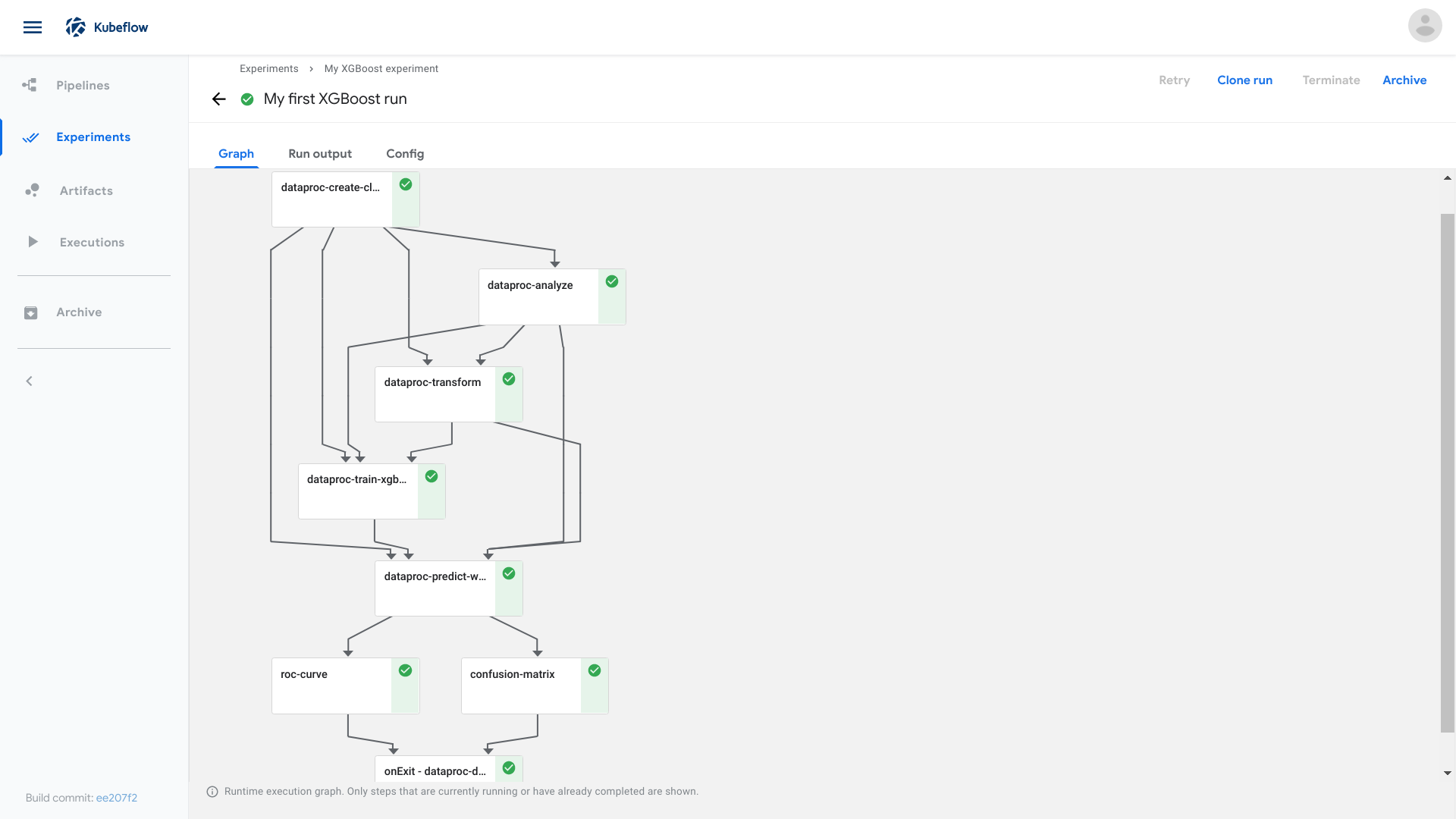
You can find the source code for the XGBoost training sample in the Kubeflow Pipelines repo.
Clean up your GCP environment
As you work through this guide, your project uses billable components of GCP. To minimise costs, follow these steps to clean up resources when you’ve finished with them:
- Visit Deployment Manager to delete your deployment and related resources.
- Delete your Cloud Storage bucket when you’ve finished examining the output of the pipeline.
Next steps
- Learn more about the important concepts in Kubeflow Pipelines.
- This page showed you how to run some of the examples supplied in the Kubeflow Pipelines UI. Next, you may want to run a pipeline from a notebook, or compile and run a sample from the code. See the guide to experimenting with the Kubeflow Pipelines samples.
- Build your own machine-learning pipelines with the Kubeflow Pipelines SDK.
Feedback
Was this page helpful?
Glad to hear it! Please tell us how we can improve.
Sorry to hear that. Please tell us how we can improve.