KFServing
Beta
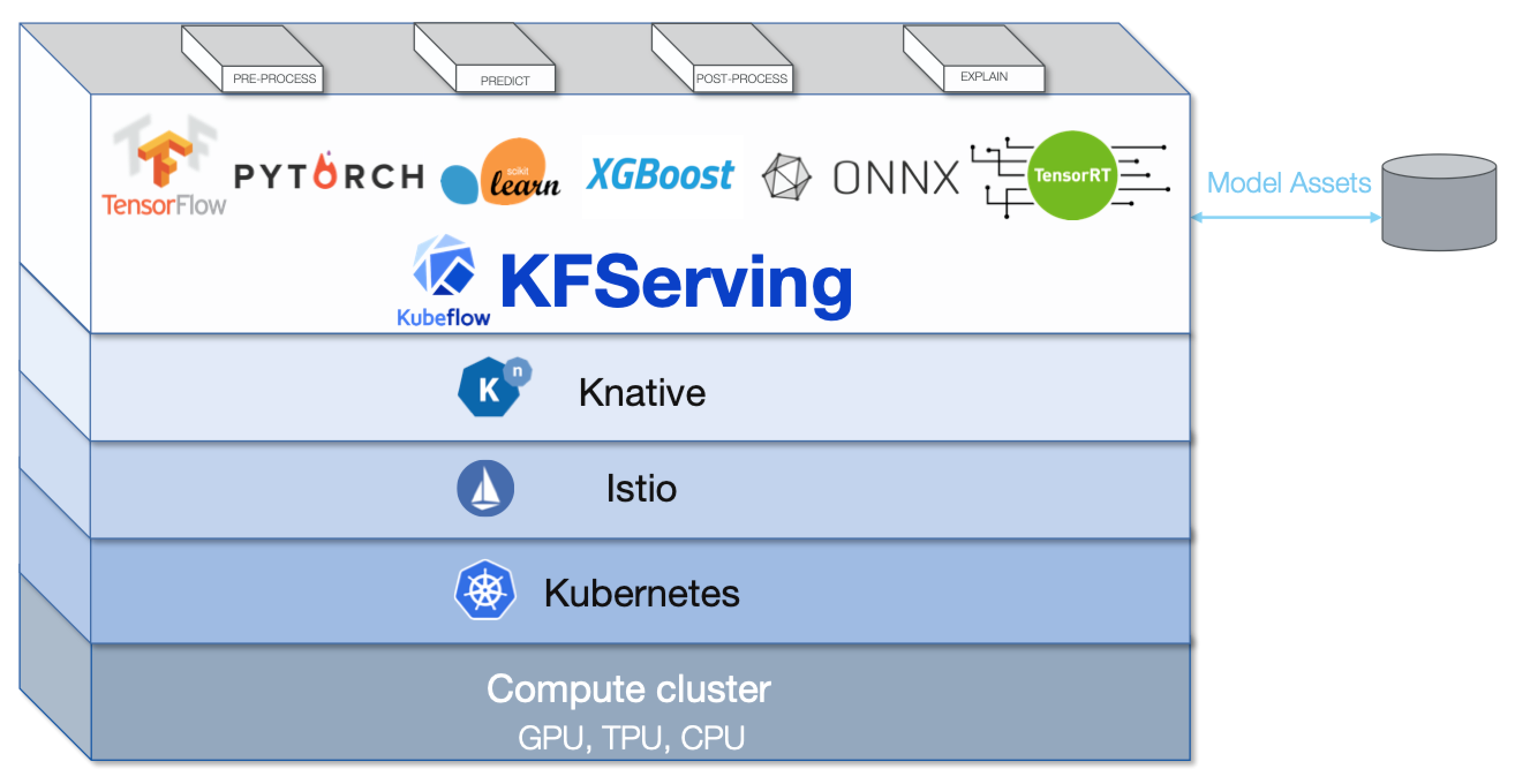
This Kubeflow component has beta status. See the Kubeflow versioning policies. The Kubeflow team is interested in your feedback about the usability of the feature.KFServing enables serverless inferencing on Kubernetes and provides performant, high abstraction interfaces for common machine learning (ML) frameworks like TensorFlow, XGBoost, scikit-learn, PyTorch, and ONNX to solve production model serving use cases.
You can use KFServing to do the following:
-
Provide a Kubernetes Custom Resource Definition for serving ML models on arbitrary frameworks.
-
Encapsulate the complexity of autoscaling, networking, health checking, and server configuration to bring cutting edge serving features like GPU autoscaling, scale to zero, and canary rollouts to your ML deployments.
-
Enable a simple, pluggable, and complete story for your production ML inference server by providing prediction, pre-processing, post-processing and explainability out of the box.
Our strong community contributions help KFServing to grow. We have a Technical Steering Committee driven by Google, IBM, Microsoft, Seldon, and Bloomberg. Browse the KFServing GitHub repo to give us feedback!
Install with Kubeflow
KFServing works with Kubeflow 0.7. Kustomize installation files are located in the manifests repo.
Examples
- TensorFlow
- PyTorch
- XGBoost
- scikit-learn
- ONNX
- Custom
- Triton
- GPU
- Autoscaling
- Pipelines
- Explainability
- Azure
- Kafka
- S3
- On-prem cluster
Sample notebooks
We frequently add examples to our GitHub repo.
Learn more
- Join our working group for meeting invitations and discussion.
- Read the docs.
- API docs.
- Roadmap.
- KFServing 101 slides.
Prerequisites
Knative Serving (v0.8.0 +) and Istio (v1.1.7+) should be available on your Kubernetes cluster.
Read more about installing Knative on a Kubernetes cluster.
KFServing installation using kubectl
The following commands install KFServing 0.2.2, using a yaml file in GitHub repo. See here for other available releases. Alternatively, you can clone the GitHub repo and run kubectl on top of it.
TAG=0.2.2
CONFIG_URI=https://raw.githubusercontent.com/kubeflow/kfserving/master/install/$TAG/kfserving.yaml
kubectl apply -f ${CONFIG_URI}
Use
- Install the SDK.
pip install kfserving - Follow the example to use the KFServing SDK to create, patch, roll out, and delete a KFServing instance.
Contribute
Feedback
Was this page helpful?
Glad to hear it! Please tell us how we can improve.
Sorry to hear that. Please tell us how we can improve.