Introduction to the Pipelines Interfaces
This page introduces the interfaces that you can use to build and run machine learning (ML) workflows with Kubeflow Pipelines.
User interface (UI)
You can access the Kubeflow Pipelines UI by clicking Pipeline Dashboard on
the Kubeflow UI. The Kubeflow Pipelines UI looks like this:
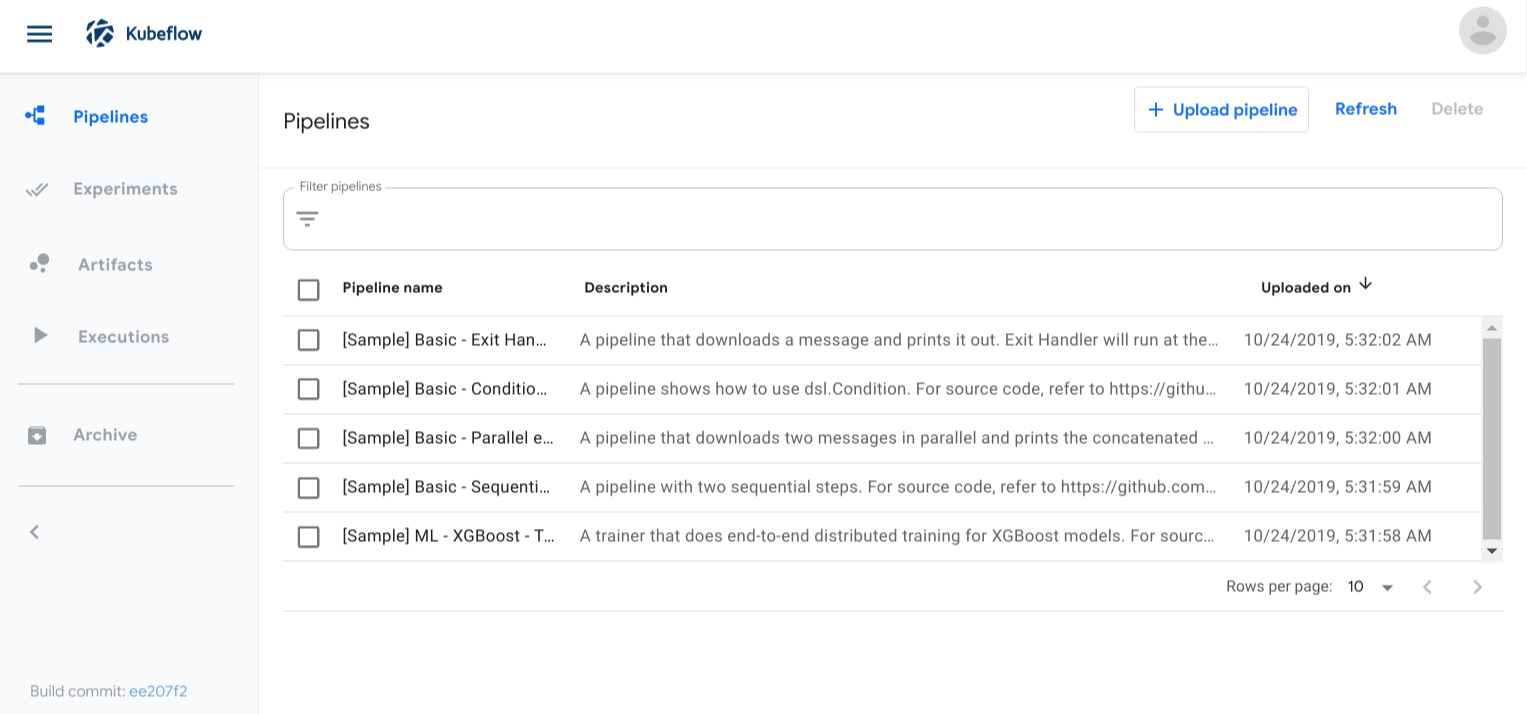
From the Kubeflow Pipelines UI you can perform the following tasks:
- Run one or more of the preloaded samples to try out pipelines quickly.
- Upload a pipeline as a compressed file. The pipeline can be one that you have built (see how to build a pipeline) or one that someone has shared with you.
- Create an experiment to group one or more of your pipeline runs. See the definition of an experiment.
- Create and start a run within the experiment. A run is a single execution of a pipeline. See the definition of a run.
- Explore the configuration, graph, and output of your pipeline run.
- Compare the results of one or more runs within an experiment.
- Schedule runs by creating a recurring run.
See the quickstart guide for more information about accessing the Kubeflow Pipelines UI and running the samples.
When building a pipeline component, you can write out information for display in the UI. See the guides to exporting metrics and visualizing results in the UI.
Python SDK
The Kubeflow Pipelines SDK provides a set of Python packages that you can use to specify and run your ML workflows.
See the introduction to the Kubeflow Pipelines SDK for an overview of the ways you can use the SDK to build pipeline components and pipelines.
REST API
The Kubeflow Pipelines API is useful for continuous integration/deployment systems, for example, where you want to incorporate your pipeline executions into shell scripts or other systems. For example, you may want to trigger a pipeline run when new data comes in.
See the Kubeflow Pipelines API reference documentation.
Feedback
Was this page helpful?
Glad to hear it! Please tell us how we can improve.
Sorry to hear that. Please tell us how we can improve.